I decided to extend the capability of TexLexan to the Business Intelligence. It seems pretencious, but I am certain that TexLexAn can do the job.
Let's think with a few questions:
- How to extract the most important information from the stream of reports, documents, mails, memos circulating in the enterprise?
- What is an important information?
- How a machine can know that one information is important and another is uninteresting?
- TexLexAn will be able to analyse this mass of texts?
- Is it able to extract the most pertinent, important and useful information from this mass of texts?
Let's answer now:
- I will try to answer to answer to first question at the end. Let's go with the 2nd. The question is pretty naïve. The information that matters concerns the future of the entreprise, its competitivity, its safety, compliance, nuisance, growth... These informations can be categorized and their values can be sorted.
- For the 3rd question, the program can search the cue words to detect the sentence carrying some important informations, it can use a classifier to extract the relevant sentences, and it can use a list of keywords extracted from the corpus to extract the most significant sentences.
- Concerning the 4th question, TexLexAn cannot analyse the totality of the documents as a whole document over a long period of time due to the volume of texts, sentences, words to analyse. The computation time will become quickly unacceptable. But the stream of documents can be summarized one by one, the summaries over a period of time can be compiled into a single document, and finally, this document can be analysed.
- The answer to the 5th question: The current versions of TexLexAn extracts the most relevant sentences and generates a summary with them. It uses the classifier, the cue words or a list of keywords to find the relevant sentence. Because it can do the same job with a list of summaries, it will be able to extract the most pertinent and important information from a mass of texts. As I explained above, it will not work directly with the documents but with their summaries.
- Now I can answer to the first question. We can imagine that TexLexAn is installed on the servers of the entreprise, and It summarizes the stream of documents is able to recognize (text, html, msdoc, odt, pdf, ppt) circulating on the intranet. Then it produces a file containing the summaries of the text analysed and date + time of the analyse (the current version does this during the archiving operation). Finally, the file of summaries will be analysed and summarized in the headquater. The new summary could cover a period of one day, one week, two weeks, one month for instance, and in consequence, it will report the most important information during the period considered.
TODO: The file containing the whole summaries exists in the folder texlexan_archive (classification.lst). I have to add a new function to texlexan allowing to analyse and summarize this file between two date. This is not very difficult!
Thursday, December 31, 2009
texlexanlauncher.xpi for Firefox
It's done and faster than I expected. My first Firefox extension works, gives the possibility to add a button to the toolbar and to launch directly texlexan with the webpage currently displayed. It's really more convenient than the drag and drop method.
The package is available on sourceforge, is named texlexanlauchner.xpi. You have to drop the small xpi package on the Firefox main window and to restart the webbrowser. Next a click on the toolbar (right button of your mouse) will open a small menu, select Personalize and drag'n drop the texlexan icon on your toolbar. That's all, there is any other configuration required.
Next you will update the python program texlexan.py to the version 0.33b or +. (texlexan.py is located in the folder ~/texlexan_prog.)
The Firefox extension and the new Python program are available here: http://sourceforge.net/projects/texlexan/files/
Screen shot of the toolbar, texlexan button is the small blue square, nothing very impressive!

The package is available on sourceforge, is named texlexanlauchner.xpi. You have to drop the small xpi package on the Firefox main window and to restart the webbrowser. Next a click on the toolbar (right button of your mouse) will open a small menu, select Personalize and drag'n drop the texlexan icon on your toolbar. That's all, there is any other configuration required.
Next you will update the python program texlexan.py to the version 0.33b or +. (texlexan.py is located in the folder ~/texlexan_prog.)
The Firefox extension and the new Python program are available here: http://sourceforge.net/projects/texlexan/files/
Screen shot of the toolbar, texlexan button is the small blue square, nothing very impressive!

Wednesday, December 30, 2009
Easy launch of TexLexAn from Firefox
I made some modification of texlexan.py. Now, It takes directly the url of the page displayed by Firefox, does the analysis. So a drag and drop of the url is no required.
To do that, you need the version 0.33 of the GUI of Texlexan in the folder ~/texlexan_prog. You can download it here: https://sourceforge.net/projects/texlexan/files/ and choose texlexan.py
and you have to configure the "Arguments" line in the "properties box" of "External Application Button" like that: -fu%addressbar%
-f means texlexan full options
u means url
%addressbar% is the address display in the address bar of Firefox.
Note: -f -u %addressbar% doesn't work.
The arguments must be: -fu%addressbar%
View of the properties box:
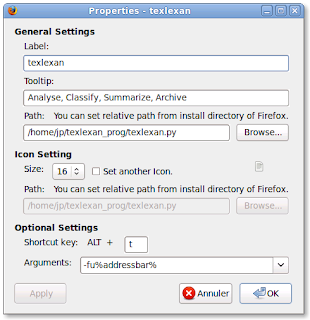
To do that, you need the version 0.33 of the GUI of Texlexan in the folder ~/texlexan_prog. You can download it here: https://sourceforge.net/projects/texlexan/files/ and choose texlexan.py
and you have to configure the "Arguments" line in the "properties box" of "External Application Button" like that: -fu%addressbar%
-f means texlexan full options
u means url
%addressbar% is the address display in the address bar of Firefox.
Note: -f -u %addressbar% doesn't work.
The arguments must be: -fu%addressbar%
View of the properties box:

Tuesday, December 29, 2009
external_application_buttons launches
As I said in my previous post, this small extension for Firefox is very interesing. It allows to launch easily other applis directly from Firefox. I think some explanation can be useful to use it with TexLexAn.
First you have to install the extension. It's easy and require less than 6 steps:
1- Drag and drop the package "external_application_for_firefox_3.0.xpi" in the window of Firefox.
2- Restart Firefox to complete the installation.
3 - Do a click right on the tool bar (between 2 buttons) and choose Personalize.
4 - Drag and drop "Application" in the tool bar and validate.
5 - At this time, you will see nothing new in the tool bar, but click right again on the position you dropped "Application". A small menu shows " New Button ... Option, Personalize". Click on New Button and a file browser will open. Go to ~/telexan_prog and select texlexan.py.
6 - Now a small icon (can be the text document icon ) is displayed. Click on this icon and the texlexan window should open.
It's done! Eventually, we can complete a little bit more the configuration.
7 - Click right on the icon and select Property.
8 - You can edit the label and the tool tip. Change the icon(*) and add a shortcut.
Note: In my case, I was not able to display the texlexan icon.
Good luck!
Jean-Pierre Redonnet.
First you have to install the extension. It's easy and require less than 6 steps:
1- Drag and drop the package "external_application_for_firefox_3.0.xpi" in the window of Firefox.
2- Restart Firefox to complete the installation.
3 - Do a click right on the tool bar (between 2 buttons) and choose Personalize.
4 - Drag and drop "Application" in the tool bar and validate.
5 - At this time, you will see nothing new in the tool bar, but click right again on the position you dropped "Application". A small menu shows " New Button ... Option, Personalize". Click on New Button and a file browser will open. Go to ~/telexan_prog and select texlexan.py.
6 - Now a small icon (can be the text document icon ) is displayed. Click on this icon and the texlexan window should open.
It's done! Eventually, we can complete a little bit more the configuration.
7 - Click right on the icon and select Property.
8 - You can edit the label and the tool tip. Change the icon(*) and add a shortcut.
Note: In my case, I was not able to display the texlexan icon.
Good luck!
Jean-Pierre Redonnet.
Monday, December 28, 2009
External application launcher for Firefox 3.0...3.5
I discover a very interesting extension for Firefox. This small application named external_application_buttons launches other application from Firefox.
It is particularly interesting for TexLexan because I think it will be possible to modify this extension to make it able to start texlexan with the current url of the page as argument.
So the user will have a summary in a new window and an archive on the disk of the current page, and that will require just one click on a button.
Probably that will take a couple of weeks to recode the "external_application_buttons" for this new job.
The addon is here: https://addons.mozilla.org/en-US/firefox/addon/12892
It is particularly interesting for TexLexan because I think it will be possible to modify this extension to make it able to start texlexan with the current url of the page as argument.
So the user will have a summary in a new window and an archive on the disk of the current page, and that will require just one click on a button.
Probably that will take a couple of weeks to recode the "external_application_buttons" for this new job.
The addon is here: https://addons.mozilla.org/en-US/firefox/addon/12892
Sunday, December 27, 2009
TexLexAn pack 1.45b
The package 1.45b corrects several bugs and adds a new functionality:
- The search engine sis returns a link to the archived document with a link to the original document. A direct link to the archived document is useful particularly when the user moved the files from on folder to an other or when a website is not available.
Note: The documents archived are compressed with bzip2 and stored in the folder /telexan_archive
The package is available here: http://sourceforge.net/projects/texlexan/files/
- The search engine sis returns a link to the archived document with a link to the original document. A direct link to the archived document is useful particularly when the user moved the files from on folder to an other or when a website is not available.
Note: The documents archived are compressed with bzip2 and stored in the folder /telexan_archive
The package is available here: http://sourceforge.net/projects/texlexan/files/
Saturday, December 19, 2009
TexLexAn : The programs

TexLexAn is an experimental set of 5 programs:
- The " analyser - classifier - summarizer " engine does the main job! The text is converted, tokenized, key terms (1-gram...n-grams) are searched, sentiments are extracted, the text is categorized (a linear classifier is used for this operation), and finally the most relevant sentences are extracted and simplified when it is possible. This program has just a CLI (no very user friendly), and it is written in language c and is strictly compliant to the Posix standard.
- The " learner " engine computes the weight of the terms and adds new terms to the knowledge base. It has just a CLI, is written in language c and is strictly compliant to the Posix standard.
- The " search " engine looks for sentence or keywords inside the list of summaries archived and retrieve the link to the original document. This program is written c in too and has just a command line interface (CLI).
- The graphic front end of the analyser-classifier-summarizer program offers an user friendly interface, allowing the drag'n drop of file or http link and the setting of the most important options. It glues several programs such as wget, bzip, pdftotext, antiword, odt2txt, ppthtml, texlexan and learner engines.
- The graphic front end of the search program is very simple. It allows to enter the sentence or keywords searched, sets some search option and lauchs the search program. The results are automatically displayed in your default web brower.

Both graphic font end programs are written in python and use the gtk libraries.
Friday, December 18, 2009
Knowledge Engineering
We are entered in the age of Innovation Economy. An age of rapid and dramatic change, an age where innovative ideas create value. Innovation will be the prime source of prosperity, particularly in our modern industrialized countries.
Knowledge, ideas and needs are fueling the innovation. Society change and new products or services are creating new needs; society change and new goods are driven by the innovation; finally, knowledge and ideas are the main source of innovations. A lot of new ideas come from new discoveries, new knowledge in fact.
The KNOWLEDGE is the main pillar of the innovation. The sum of knowledge and the stream of information exceed the capacity of one human. The consequence is the knowledge is split in thousand of specialities that individual human being can handle. Each specialist has a deep knowledge of a small number of topics.
Today, any major innovations involve the deep knowledge and understanding in many fields. Only a few big companies can afford to have hundred of specialists, but it is not enough, the communication between them must be efficient and, of course, should not cost the main part of their time!
When I started to work as process engineer and lab manager, in a computer tape and floppy disks manufacturing company, quickly I understood that many scientific and technical fields where involved, such as: the magnetism, the rheology of polymers and dispersions, the cross-linking of polymers, the lubricants, the polymers degradation, the errors detection and correction algorithm, the applied statistics... , that was 23 years ago!
It is an obligation to manage the knowledge efficiently, if we want to continue to innovate. Only a machine can analyse, extract pertinent information, compare information, regroup information, archive and retrieve information coming from thousand of papers, publications, web sites and blogs.
The power of the personal computer, the omnipresence of internet incited me to write TexLeAn.
Today, TexLexAn is able to do some basic operations on a text document,
such as :
- Estimate the reading time and its difficulty.
- Evaluate the sentiments expressed (positive or negative sentiments).
- Extract the keywords.
- Categorize (or classify) the document.
- Summarize by extraction of the relevant sentences.
- Archive the document.
- Search in the archived summaries and retrieve documents.
In the future, TexLexAn will be able to:
- Regroup the documents (clusterization) per topics.
- Compare documents and extract similarities and divergences.
- Summarize a group of documents.
Knowledge, ideas and needs are fueling the innovation. Society change and new products or services are creating new needs; society change and new goods are driven by the innovation; finally, knowledge and ideas are the main source of innovations. A lot of new ideas come from new discoveries, new knowledge in fact.
The KNOWLEDGE is the main pillar of the innovation. The sum of knowledge and the stream of information exceed the capacity of one human. The consequence is the knowledge is split in thousand of specialities that individual human being can handle. Each specialist has a deep knowledge of a small number of topics.
Today, any major innovations involve the deep knowledge and understanding in many fields. Only a few big companies can afford to have hundred of specialists, but it is not enough, the communication between them must be efficient and, of course, should not cost the main part of their time!
When I started to work as process engineer and lab manager, in a computer tape and floppy disks manufacturing company, quickly I understood that many scientific and technical fields where involved, such as: the magnetism, the rheology of polymers and dispersions, the cross-linking of polymers, the lubricants, the polymers degradation, the errors detection and correction algorithm, the applied statistics... , that was 23 years ago!
It is an obligation to manage the knowledge efficiently, if we want to continue to innovate. Only a machine can analyse, extract pertinent information, compare information, regroup information, archive and retrieve information coming from thousand of papers, publications, web sites and blogs.
The power of the personal computer, the omnipresence of internet incited me to write TexLeAn.
Today, TexLexAn is able to do some basic operations on a text document,
such as :
- Estimate the reading time and its difficulty.
- Evaluate the sentiments expressed (positive or negative sentiments).
- Extract the keywords.
- Categorize (or classify) the document.
- Summarize by extraction of the relevant sentences.
- Archive the document.
- Search in the archived summaries and retrieve documents.
In the future, TexLexAn will be able to:
- Regroup the documents (clusterization) per topics.
- Compare documents and extract similarities and divergences.
- Summarize a group of documents.
Subscribe to:
Comments (Atom)